 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文2019-01-23 关键词:医疗AI
《PLOS Medicine》发表的一项新研究发现,机器学习模型比传统方法更能准确预测高风险患者手术并发症的发生率,在灵敏度、特异性方面优于人类专家和现行通用的风险预测计算器,AUC值最高达0.924。
研究人员表示,该模型基于真实临床大数据,在数据清洗、临床特征提取和结构化数据基础上构建预测模型,具有强大的风险预测能力,且能够准确分类不同风险级的患者,帮助医生科学决策。
比专家更“专业” 机器学习模型AUC值达0.924
该预测模型的研发和训练基于研究团队利用自动化SQL、R代码创建的数据库,数据库提取了3700万条患者病历数据,形成了194个临床特征包括患者人口统计学(例如,年龄,性别,种族)、吸烟史、用药情况、合并症、手术信息等。
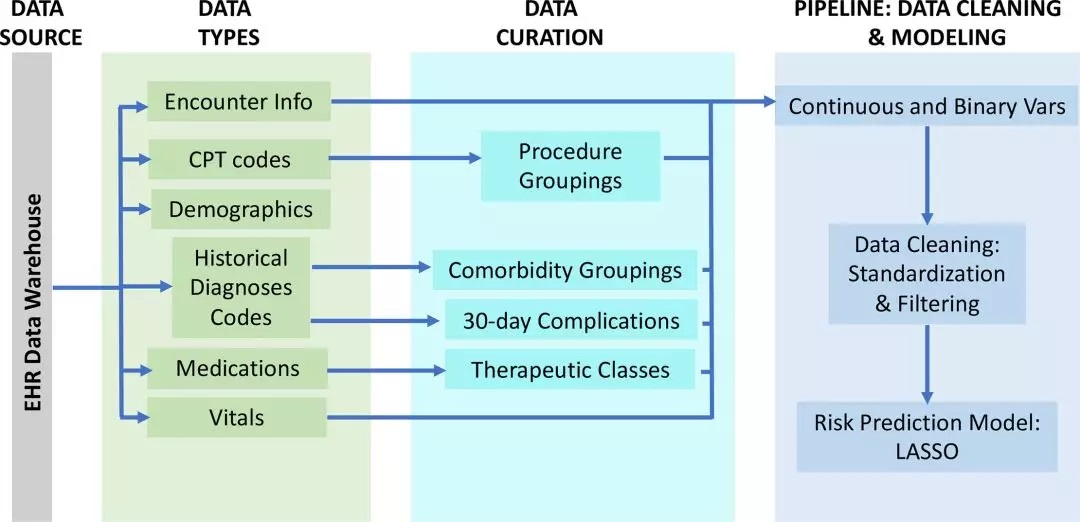
为验证模型用于围手术期患者术后并发症的风险率预测能力,研究人员选取某医疗机构2014年1月1日至2017年1月31日期间66,370名涉及99,755例有创手术的患者队列作为此次研究的测试数据,这些患者平均术后并发症和30天术后死亡率分别为16.0%和0.51%。
经过多次交叉验证,模型显示出了强大的预测能力,研究得到AUC值介于0.747和0.924之间。
研究团队将人类专家的临床表现与机器学习模型进行了比较,发现:在阳性预测值(PPV)方面,机器学习模型超过了人类专家,PPV为37.92%,而专家的PPV为22.47%,这意味着:模型的风险预测能力比医生更精准。

机器学习模型在识别高风险患者方面也比临床医生更“火眼金睛”,灵敏度为77.24%,而人类专家的灵敏度为73.45%,高风险阈值被定义为“任何并发症的风险为15%”。此外,机器学习模型的特异性达到了74.92%,与人类仅49.74%的特异性相比,该模型较少错误分类低风险患者,有利于诊疗决策的规范化与医疗费用的合理性。
风险预测能力胜过最好的风险计算器
除了预测能力表现优于人类专家外,机器学习模型还超过了通用的风险计算器ACS NSQIP——美国外科医师学会(ACS)全国手术质量改进计划(NSQIP)的通用外科风险计算器,其是一种在线决策的支持工具,它通过分析患者的临床特征来预测术后发生不良事件的风险,该计算器是目前使用最广泛的手术前风险预测模型。
研究显示,机器学习模型的AUC值为0.79,而NSQIP计算器的AUC值为0.67。机器学习工具也获得了比NSQIP计算器更高的灵敏度,分别为0.9167和0.7500,以及更高的特异性,分别为0.5873和0.5556。
研究人员表示,机器模型建立在实时的EHR数据提取基础上,可以持续智能更新。NSQIP计算器则采用人工手动提取的患者数据,很难实时获取电子病历中患者的最新临床数据或及时调整临床新变量。
研究人员指出,该工具的表现优异,为临床医生提供了患者术后风险评估的改进方法和节约诊疗成本的可能性。美国外科手术的并发症发生率达15%,高风险手术并发症的发生率高达50%,美国每年因手术并发症产生的治疗总费用约为313.5亿美元。
研究也有其局限性,研究人员表示,未来的研究需要增加其他数据来源,以进一步评估模型预测高风险患者的能力。尽管如此,研究结果证明了利用单一组织的EHR数据构建机器学习模型预测外科手术并发症风险是切实可行的。
参考文献:https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.1002701
成为我们的
合作伙伴