 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文2021-12-23 关键词:临床决策支持(CDSS)
医疗数据质量(DQ)影响着临床决策支持系统(CDSS)的性能,也是实现数据复用的重要因素。因此,通过数据质量评估发现问题、管理问题是释放数据价值的关键,但目前国内外仍缺乏各应用场景所需数据的质量评价方法与评估标准,增加了数据质量评估工作的复杂性与挑战性。
近期,一项发表在BMC Medical Informatics and Decision Making的研究显示,利用机器学习算法不仅能高效评价数据质量,也可挖掘校验数据质量的适用规则,以确定数据集是否适用于特定应用场景。
聚焦数据问题及其对CDSS预测的影响
设计三大研究步聚
由于不同的AI应用对底层数据的需求不同,为确定特定场景的数据质量评价方法与标准,传统的做法是研究既有的质量评估框架、咨询专家等,而该研究旨在评估机器学习算法在数据质量评估中的适用性,以减少对专家意见与人工操作的依赖,探索新型数据治理方法。
该研究流程共设计了“数据准备—数据质量评估(DQA)—机器学习”三大步骤(图1),其中在数据准备阶段,研究人员首先虚构了一个基于患者病史数据进行心脏病风险预测的CDSS场景,预先定义输入数据的质量如何影响CDSS预测性能,以评估通过机器学习算法获得的数据规则是否正确。
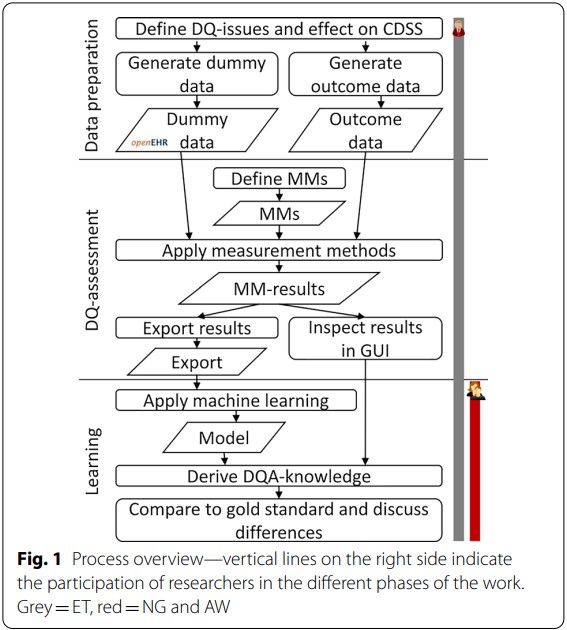
图1 研究流程设计
其后,研究人员使用开源的模拟数据生成器生成了10500个符合openEHR规范的数据组合,每个组合代表一个病例,将其不等分配至20个虚拟医院,数据储存于openEHR中。这些数据根据文献知识预先设定了不同类型的质量问题,例如,“缺失血压测量记录”是明显的数据问题,会使CDSS预测性能大打折扣;而“心率测量次数少于10”作为次要性问题,只让CDSS性能略微降低。
由于机器学习算法模型训练需用到带标注的数据集,研究人员同时从数据储存库中生成不同数据问题对应的CDSS预测准确率,并对预测结果进行多次验证,确认无误后作为结果数据添加到数据集中。
在“数据质量评估”(CAQ)阶段,研究人员使用了开源工具openCQA进行质量评估,根据每个病例、每家虚拟医院的不同数据变量,生成半自动的测量方法(MM),例如,测量某病例所有收缩压测量值的平均值和医院整体平均值。并将各测量结果数据集导出,一是用于机器学习算法训练,二是使用openCQA的GUI检查预设的数据质量问题是否“可视”。
在GUI视图中,研究人员找出了病例存在的数据质量问题,同时评估其对CDSS预测产生的影响。如图2所示,第一个表格标黄的行列表示“缺失血压值记录的病例”,第二个表格则相应地标出了该问题导致的CDSS成功值为“0”。由此合理假设研究人员可以识别其中的关联,从而推导出该CDSS场景下的数据质控规则,与机器学习算法推导的结果进行比较。
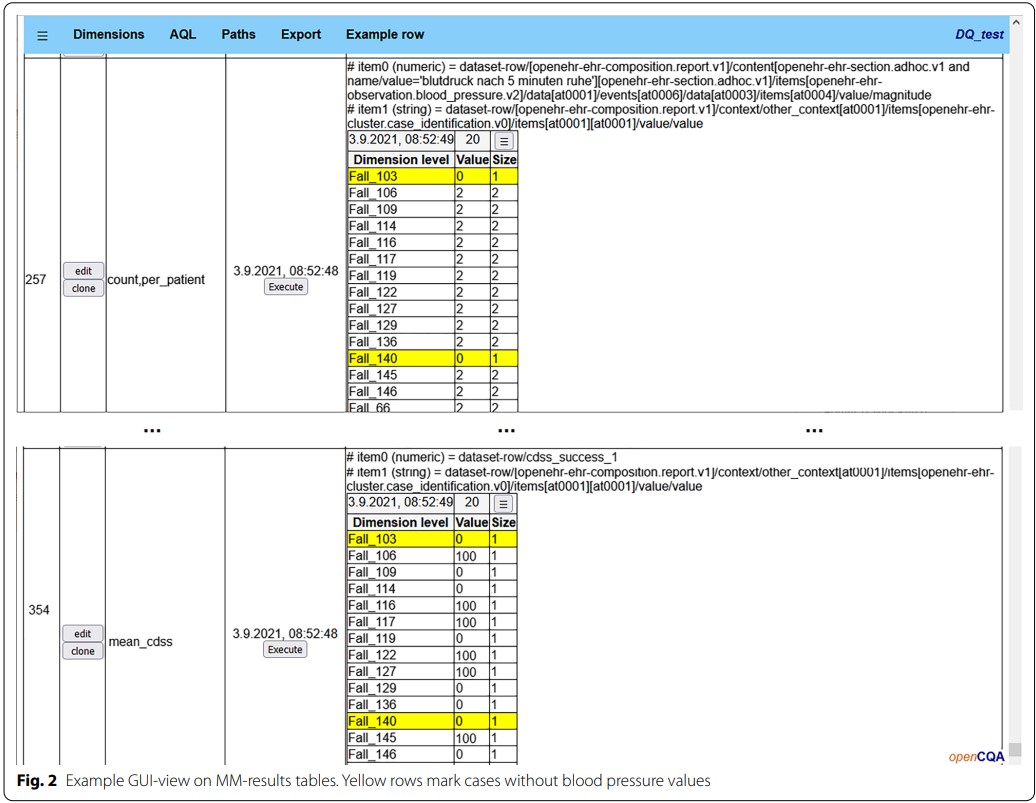
图2 在GUI中检查结果
为确保研究结果的合理性,3名研究人员中只由研究人员ET全程参与研究并检查GUI的结果,另外2人则只参与了第三阶段的机器学习研究,并对预设的数据质量问题一无所知。
人工手动巡检与AI结果对比
“从应用结果倒推”
在机器学习研究阶段,研究人员选择了机器学习算法中的决策树(DTs)算法,因为DTs易于解释,且对数据没有归一化等特殊要求;然后使用DAQ阶段产生的数据集进行算法模型训练。而DTs应用包括两个方面,一是从所有虚拟医院的数据中确定测量结果;二是对每个病例的数据测量结果进行汇总。
应用DTs目的是通过解释“树”,从决策节点上推导影响CDSS性能的数据问题规则。下图3是从决策树中分离出来的示例,这9018个病例(占病例总数的88%)的CDSS预测准确率为60%,根据每个病例有无收缩压测量值分为两组,一组病例无测量值(191例),CDSS准确率为0;另一组病例有一个或多个测量值(8827例),CDSS预测准确率为62%。
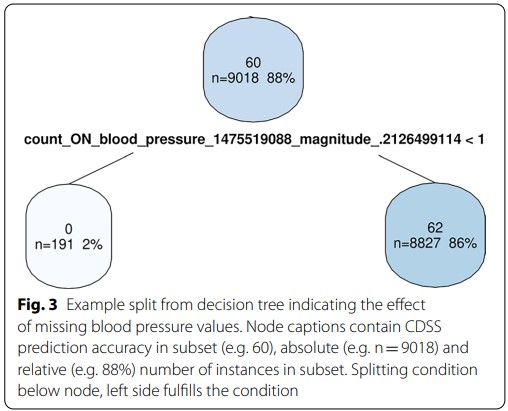
图3 决策树示例
这个示例提示了数据质量问题及其带来的影响,也说明了研究人员采用“从应用结果倒推”的方式进行数据质量问题巡查。
由于研究人员ET了解预设的数据质量问题及对CDSS预测的影响,能够对DTs提取的规则与实际问题进行比较。在该研究中他执行了3次机器学习工作流程,随之也作出了3个DTs应用评价;而另外两名研究人员只凭决策树解释推导出一个规则列表,并将规则列表与实际数据问题评价标准进行比较,得出比较结果“Control”,如图4所示
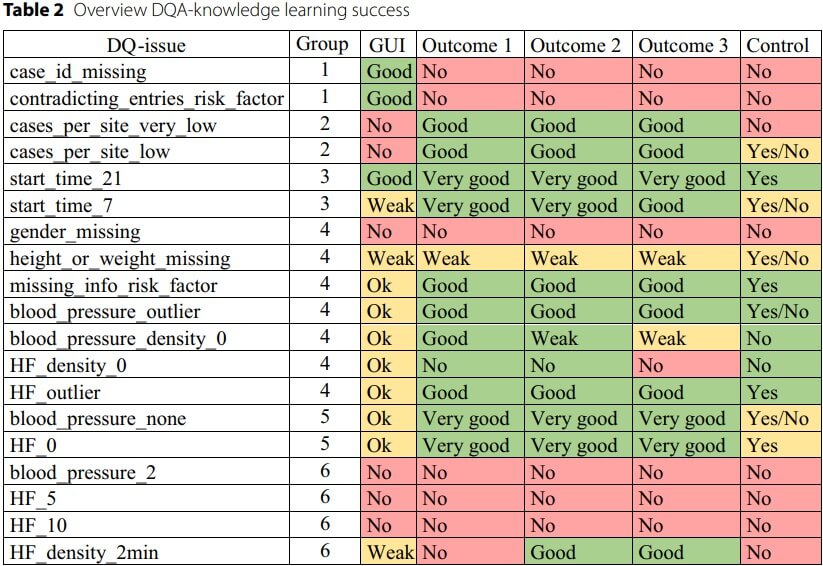
图4 数据质量评估结果对比
图4作为该研究的最终结果,其中DQ-issue代表实际存在的质量问题,GUI代表研究人员ET手动巡检的结果,用Good、Weak等评价巡检结果中覆盖的实际数据问题数及对CDSS的影响;Outcome 1、Outcome 2、Outcome 3则是他对决策树算法的3个评价;Control中的 “Yes”代表另外两名研究人员都将该数据问题作为CDSS的影响因素,“yes/no”表示他们中只有一人获得这种认知。
根据图4的多方比较显示,19个实际存在的数据问题,11/12个能在决策树算法中“捕捉”,其中至少9个问题能被两位“不知情”的研究人员从树解释中推导出来;此外,由于决策树算法较手动巡检发现了更多的数据问题,且能更好地展示对CDSS性能的影响,所以获得的评价也更优。反映其能作为手动巡检的有效补充工具,助力建立特定CDSS场景所需数据集的评价标准(例如应具备哪些数据变量,每个变量的阈值等),通过数据治理有效提高CDSS预测性能。
研究人员表示,此次研究目的并非评价机器学习算法性能,而是考量其在数据质量评估工作中的适用性。
参考文献:
Tute Erik,Ganapathy Nagarajan,Wulff Antje. A data driven learning approach for the assessment of data quality[J]. BMC Medical Informatics and Decision Making,2021,21(1):
成为我们的
合作伙伴