 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文2021-8-12 关键词: 医疗AI
心血管疾病(CVD)是全球导致死亡的主要原因,研究与其发病相关的危险因素,开发有效的CVD预测模型一直是医学热点。近期,一项发表在 Diagnostics的研究显示,基于机器学习算法与居民健康检查数据集的CVD预测模型更经济高效,易于应用。
文章中提到,该研究验证了多种机器学习算法对CVD的预测性能,其AUROC均值最高为0.812,优于既有的CVD预测模型;且在纳入研究的38项相关危险因素中,患者既往CVD病史是影响预测准确性的最重要因素。
01
AUROC均值最高0.812
预测性能优于既有风险评估模型
研究人员表示,以往关于CVD危险因素和预测模型的研究大多通过患者访谈、医院病历等获得分析数据,但由于个体发病风险包括生理因素、社会心理因素、行为因素等,利用临床数据构建预测模型存在局限性,且传统研究方法需要花费大量的时间与精力来获取与分析数据。该研究纳入韩国国民健康保险服务(NHIS)的健康检查数据库,并应用机器学习算法进行CVD预测,可以开发一种成本效益高、可靠的工具。
该研究从NHIS数据库中共抽取了9398例数据,其中一半为有明确诊断的CVD患者,另外一半则为未患有CVD受试者,由于CVD发病率很大程度受年龄和性别的影响,两组数据集均选取了45岁以上的人群且性别比例相同;并选择数据中的总胆固醇(TC)、低密度脂蛋白胆固醇(LDL-C)等38项变量用于机器学习算法建模,最后使用两组数据集进行预测模型训练与验证,根据四次交叉验证的测试结果计算出受试者工作特征曲线下面积(AUROC)。
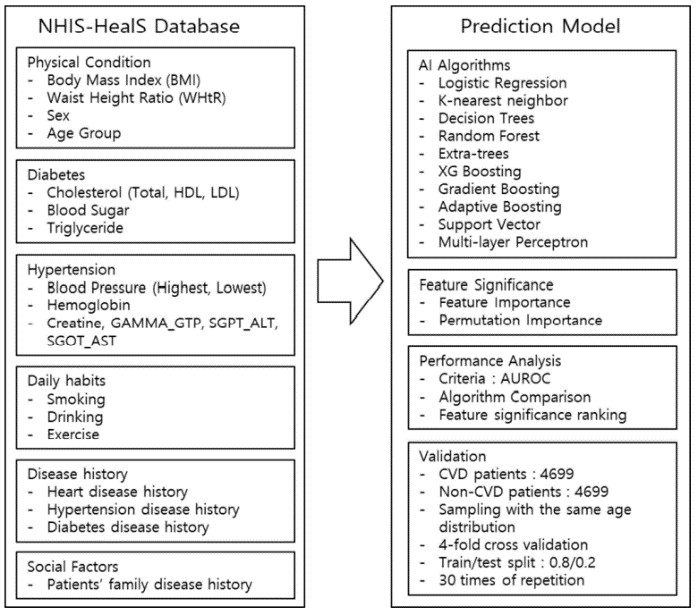
图1 预测模型的研究过程与体系结构
为比较不同机器学习(ML)算法的预测性能,研究团队使用了Logistic回归、决策树、随机森林、极端梯度提升、梯度提升等10种算法进行建模,每个模型重复相同的验证30次,以抵消随机抽样的影响。由此计算出每种算法模型AUROC的最小值、最大值、平均值,进行性能排序。结果显示,极端梯度提升、梯度提升、随机森林3种算法表现出的性能最优,其AUROC平均值依次为0.812、0.812、0.811,最大值依次为0.822、0.821、0.821(图2-3)。
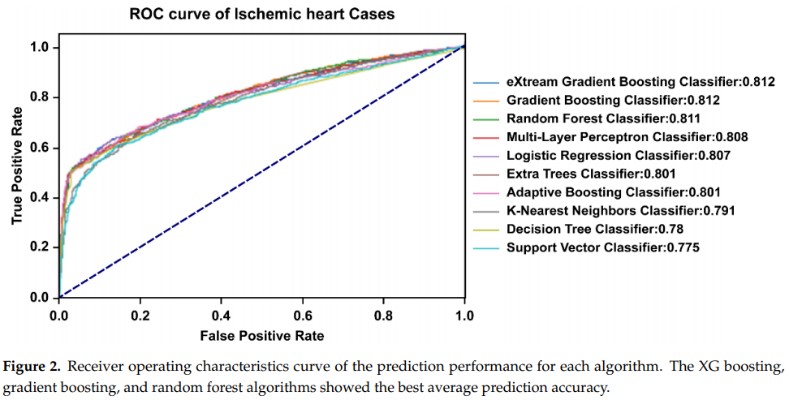
图2 不同算法模型的ROC曲线
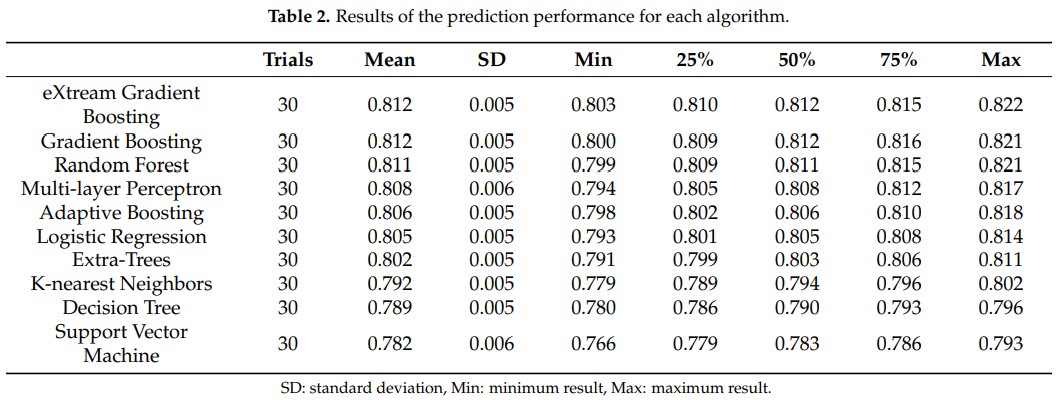
图3 不同算法模型的测试结果
研究人员将预测结果与既往已发表的验证研究进行了对比,表示在相关研究中,ACC/AHA评估模型的AUROC为0.73-0.74,Framingham风险评分的AUROC为0.62-0.88,相对而言,算法模型的性能表现更稳定、更优。此外,国际上也有不少关于ML算法预测的研究,其结果均优于人工评估,但由于本研究只使用了38个变量,远少于同类研究,例如一项研究中使用了473个变量。所以作者认为其提出了一种简单、易用、性能高的新CVD预测模型。
02
38个危险因素
既往CVD史对预测性能“贡献”最大
研究人员表示,一般来说,高血压、糖尿病、高脂血症等是引起CVD的主要危险因素,为了验证相关因素对算法预测结果的影响,他们利用随机森林算法的特征重要性、置换重要性两种方法进行分析比较,得出哪些因素对预测模型的性能“贡献”最大。
结果显示,在基于特征重要性方法的分析中,既往CVD史在38个危险因素中排名第一,是影响ML预测准确性最重要的因素,其次是TC、LDL-C、腰高比和BMI指数(图4);而置换重要性得出的前5位排序与其相同,前10位排序结果则有所差异(图5)。
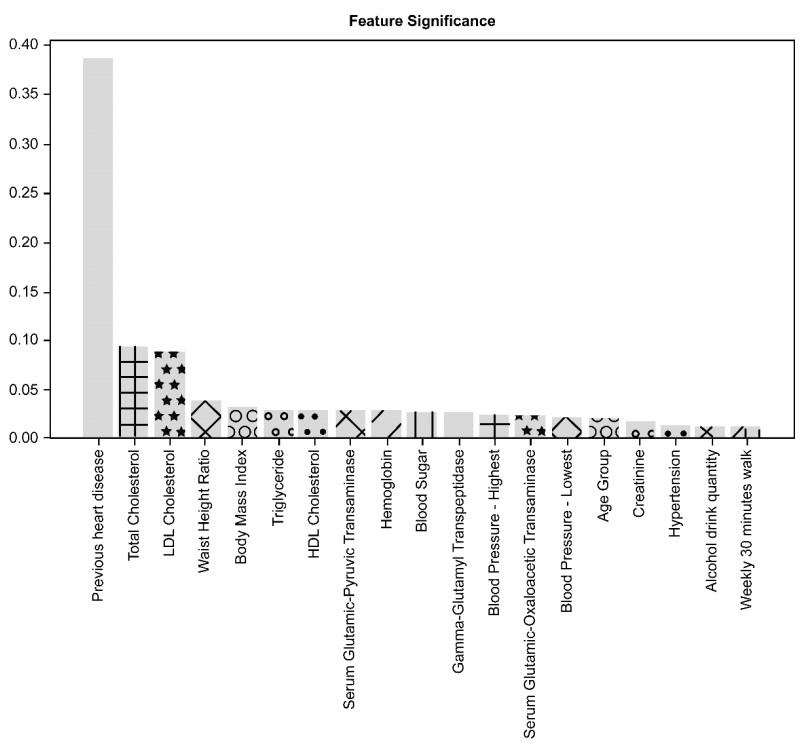
图4 基于特征重要性的排序结果
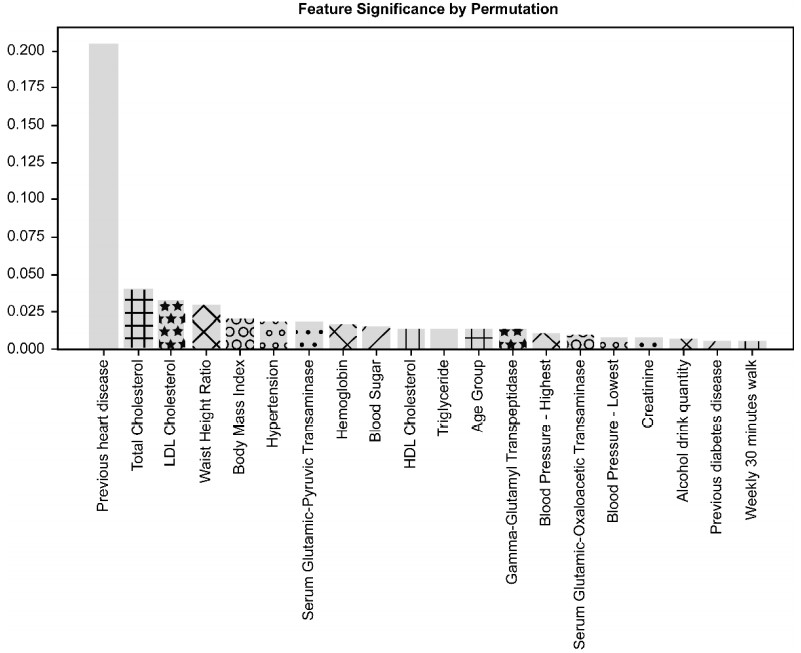
图5 基于置换重要性的排序结果
研究人员表示,既往CVD史、TC、LDL-C都是已被临床证明的CVD复发或风险预测的重要危险因素,值得注意的是,在本研究中,与体型相关的腰高比、BMI指数都表现出了较实验室结果更大的重要性,再次印证肥胖与CVD密切相关。
文章最后指出,本研究有一定的局限性,首先是数据集不包括详细的临床数据,不足反映受试者准确的身体状况;其次,仅在单一种族群体中进行CVD预测或导致选择偏差,希望未来可以收集全球不同种族人群的健康检查与临床数据集,由此构建起全球适用的CVD预测模型。同时表明,构建更准确的CVD预测模型的关键是高质效地收集、共享与分析研究数据集。
参考文献:[1] Kim Joung Ouk Ryan, Jeong YongSuk, Kim Jin Ho, Lee Jong Weon, Park Dougho, Kim HyoungSeop. Machine Learning-Based Cardiovascular Disease Prediction Model: A Cohort Study on the Korean National Health Insurance Service Health Screening Database.[J]. Diagnostics (Basel, Switzerland),2021,11(6):
想了解更多产品信息或预约产品演示?我们的专业团队随时为您服务