 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文编者按:
本期 @攻城狮栏目邀请了惠每科技高级算法专家吴哲夫,介绍处理各类医学命名实体识别(NER)问题所使用的模型策略“组合拳”。这组方案由惠每科技算法总监全福亮设计,在国内权威中文医疗信息处理挑战榜CBLUE的CMeEE单项任务评测中,以领先的医学命名实体识别能力获69.626分,在该项任务中排名第三。
惠每科技在CMeEE单项任务评测中选择的医学预训练模型为HMBert,HMBert的构建背景与比赛方案如下:
01
HMBert的构建背景
CDSS中的智能业务包括辅助决策、医疗质量控制、患者画像、病历质控、数据上报等,而AI算法是完成上述目标的重要一环。惠每科技自成立以来,就致力于利用CDSS技术提升医疗质量,目前已形成一套完整的AI算法基础服务和临床应用流程。
在各项AI基础算法服务中,自然语言处理(NLP)技术是其中最重要的一环。涉及到NLP技术的主要算法任务包括医学命名实体识别(NER)、医学实体关系抽取(NRE)、医学知识图谱构建、医学实体标准化等。
因为Transformer(谷歌提出的模型,在NLP、计算机等领域都取得了巨大的成功)的红利,当前很多算法任务是基于Bert预训练模型来达到最好效果。为此,我们也构建了一个医学预训练模型HMBert,来应用到基础算法服务中。
HMbert使用了公司内医生专家整理的各种专科文献资料、论文书籍,并从网络百科中搜集更多的数据等,采用多种mask的策略,经过多轮的训练学习,生成了可供CDSS业务使用的基础预训练模型,提升医学命名实体识别能力。如图1。
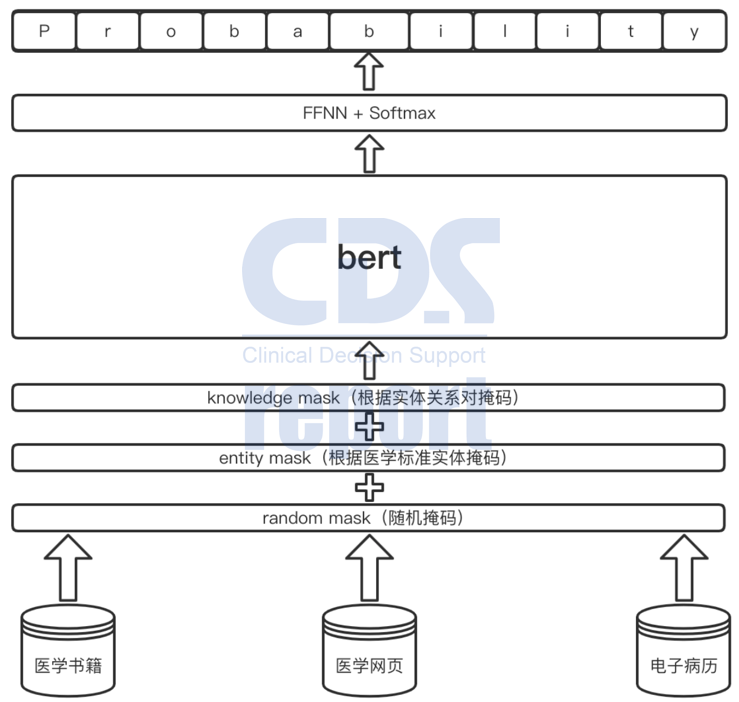
图1 HMbert构建流程
02
CMeEE任务与NER分类
惠每医学预训练模型HMbert参与的CMeEE评测任务共包括9大类实体:疾病(dis),临床表现(sym),药物(dru),医疗设备(equ),医疗程序(pro),身体(bod),医学检验项目(ite),微生物类(mic)和科室(dep)。其中,“临床表现”实体类别中允许嵌套,即允许存在其他八类实体。
例如,在span“呼吸中枢受累”中,存在两个实体嵌套:“症状:呼吸中枢受累”和“部位:呼吸中枢”。嵌套实体是医学文本中常见的现象,也一向是NER任务中一个难点。因此在模型处理上要比通常的医学命名实体识别模型复杂。
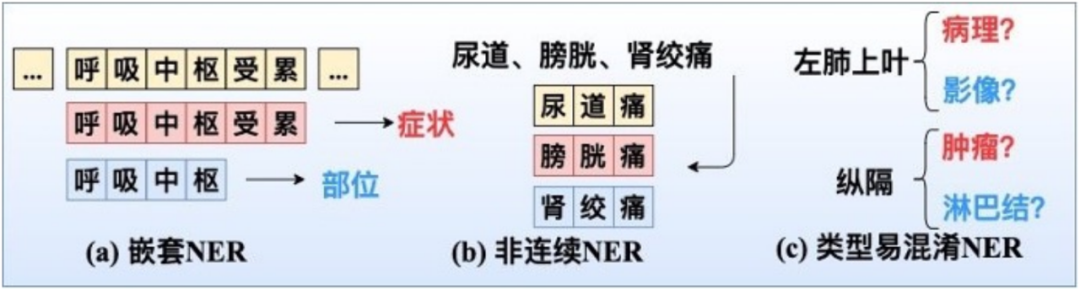
除了嵌套实体,实际业务中遇到的NER类型还包括:普通、非连续的NRE、易混淆的标注这几种。其中“非连续的NER”可以上图为例,在“尿道、膀胱、肾绞痛”中存在三个非连续实体“尿道痛”、“膀胱痛”、“肾绞痛”。
而“易混淆的标注”是一项特殊的关注度较低的业务类型,例如对于部位实体“左肺上叶”,其归属于“病理”还是“影像”模块?对于“纵隔”部位,是属于“肿瘤”还是“淋巴结”部位?可能得依据病历文书位置和前后文进行判断。
为解决不同的NER问题,行业使用的医学命名实体识别框架主要包括:序列标注法、基于超图法、序列到序列准换法、基于span标注法这四种,而2022年行业一篇新发表的论文,提出使用一个统一框架——词对关系分类(W2NER)来解决当前问题,我们可暂列为第五种。
对于NER模型的选择,没有固定的套路,新技术要不断的尝试更新,方法策略要不断的迭代,实际使用场景的好坏还与医疗数据标准化、后结构化、知识图谱和规则引擎和适配性息息相关。
03
CMeEE任务评测中所使用的NER策略
针对CMeEE任务评测中的医学命名实体识别问题,我们主要制定了“HMBert+span标注+数据增强+对抗训练+w2ner”模型策略组合拳,这套方案不仅在CMeEE任务中获得Top3的排名,在实际业务场景中也获得较好的效果,以下将对其中的三项策略进行逐一讲解。
1、Span标注
span标注作为常用的医学命名实体识别框架之一,又可细分为指针网络、MRC、token-pair、span片段四种主流的方式。相较于传统的序列标注的方法,Span标注的方法能够很好的处理嵌套和不连续的问题,并且泛化能力较强。缺点是对于传统序列标注中只需要学习一层的标注目标,span标注的方式也决定了学习目标结构的增大,因此会有更多的效率损失。
图3-4展示了不同的span标注方式的医学命名实体识别效果:
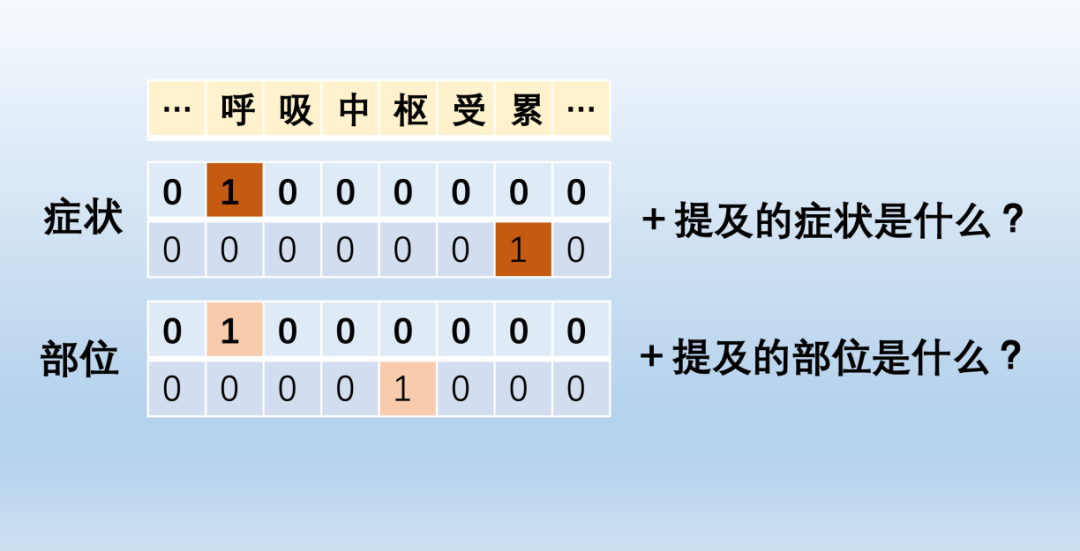 图3 指针网络+MRC的图示
图3 指针网络+MRC的图示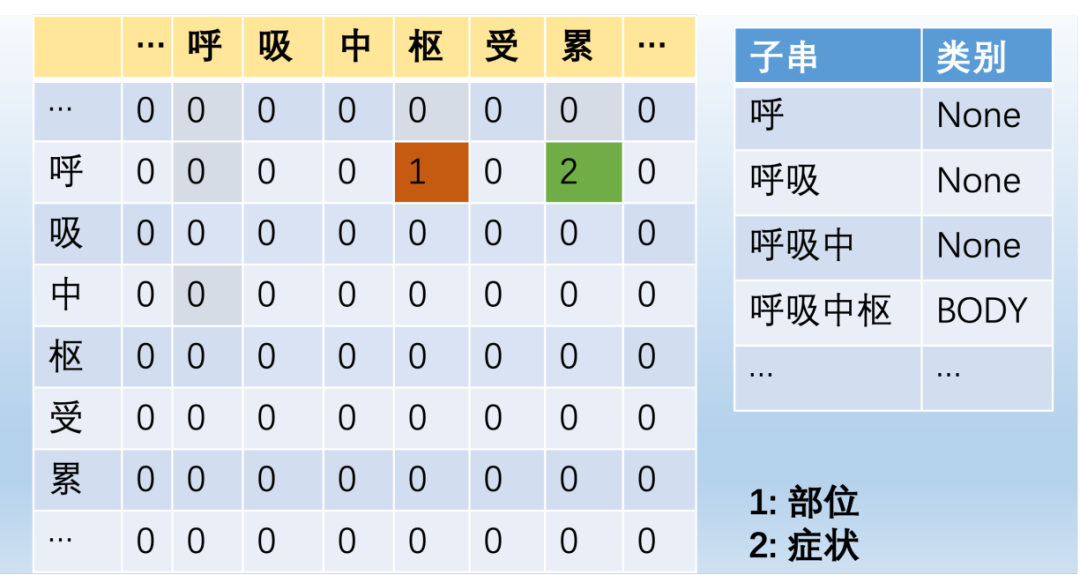 图4 Token-Pair+span片段的图示
图4 Token-Pair+span片段的图示 2、数据增强
数据增强(Data Augmentation, DA)的提出主要为了解决深度学习中数据不足的场景,当前我们应用在NLP的领域,主要是为了增加数据的多样性,提高模型的泛化能力。
数据增强是指通过对数据添加微小的改动或从已有数据合成新的数据,来增大样本数量的方法。对于连续型的任务,我们可以对于数值进行微小的扰动,但对于NLP这种离散型的任务,应用的难度会更高。主要有三种策略:
数据增强
- demo:一个身着白衣和牛仔裤的人站在那儿
基于语义的增强
- 对于某些近义词进行替换
- demo:一个身穿白色毛衣和牛仔裤的人站在那儿
基于噪声的增强
- 人为增加无意义的噪声数据
- demo:一个人身着白衣和牛仔裤的人站在那儿
基于采样的增强
- 从新的数据集中采样符合当前数据分布的数据
- demo:那儿站着一个身着白衣和牛仔裤的女孩
当然,具体应用到NLP领域,有很多方法可以选择,比如基于语义的增强,如何才能定义成为近义词,就有很多方案可以选择。有时候,一些具体的方法实际可能混合了三种策略中的多种,具体可以针对于目标问题做各种尝试,达到固定数据集或目标上的最好效果。在我们的比赛中,就采用了几种混合的策略,
3、对抗训练
对抗训练是AI工程师常见的模型策略,同样是增加模型鲁棒性的方法,其与数据增强的区别是:数据增强更多的是通过外在策略,在模型训练前进行数据的变换;而对抗训练更多是在模型的学习过程中的一些策略。
常见的对抗训练的方法包括:1、添加噪声:比如在输入层增加高斯噪声、中间层增加Dropout、对图像进行随机平移等。2、添加罚项:比如L1、L2罚项、梯度惩罚等。
上面不同策略和方法对于CMeEE任务目标提升的表现如下图: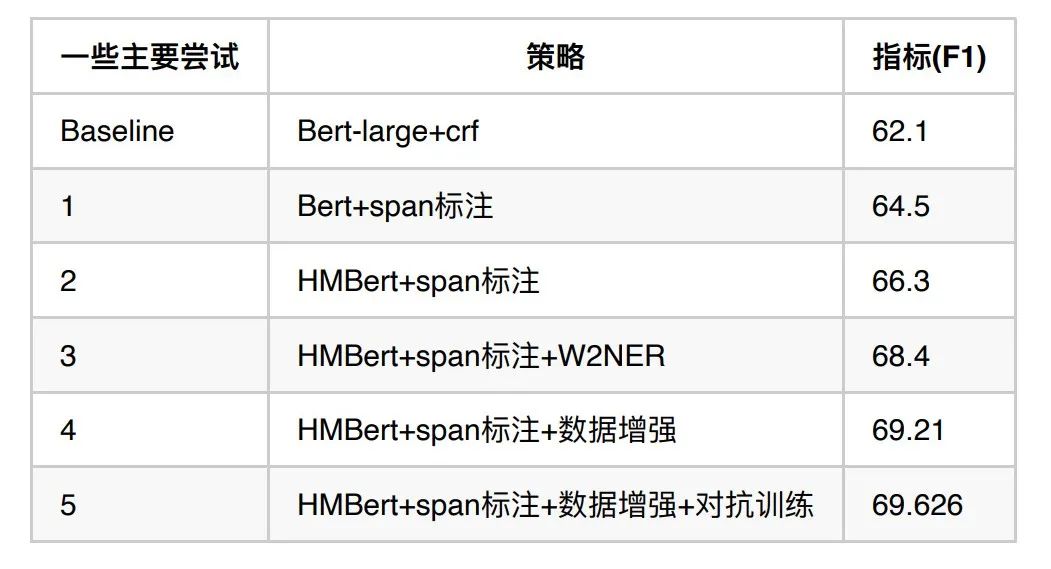

图5 2022年6月HMBert在CMeEE中的评测结果截图
 特邀专家:吴哲夫-惠每科技高级算法专家
特邀专家:吴哲夫-惠每科技高级算法专家想了解更多产品信息或预约产品演示?我们的专业团队随时为您服务