 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文2023-11-03 关键词: 医疗大模型
近日,为验证惠每医疗大模型的计算能力和语言生成能力,惠每算法团队报名参加了第九届中国健康信息处理大会(CHIP 2023)评测任务,并分别获得了CHIP-PromptCBLUE医疗大模型评测和中文糖尿病问题分类评测两项任务的第一名。
两项任务综合评分荣获两个第一
CHIP2023是中国中文信息学会(CIPS)医疗健康与生物信息处理专业委员会主办的关于医疗、健康和生物信息处理和数据挖掘等技术的年度会议,是我国健康信息处理领域最重要的学术会议之一。会议聚焦“大模型与智能医疗健康”,聚集全国顶尖的医学信息处理学者与医疗专家,共同探讨大模型时代下智慧医疗健康发展的趋势与挑战,以及人工智能医疗应用落地新路径和医学研究新方法。
此前,CHIP2023发布了6项测评任务,惠每科技算法团队参加了其中两项:CHIP-PromptCBLUE医疗大模型评测任务和中文糖尿病问题分类评测任务。

为推动中文大模型在医疗领域的落地,华东师范大学王晓玲教授团队联合天池团队推出了首个中文医疗场景的LLM评测基准——PromptCBLUE。在本次任务中,主办方推出的CHIP-PromptCBLUE-v2评测任务是CCKS-PromptCBLUE评测任务的全面升级:新增Text2DT和CMedCausal两个任务,对LLM提出更高挑战性;将94个prompt模板提升到450个,对LLM的鲁棒性要求更高;设置不微调赛道和参数高效微调赛道,考察上下文学习、参数高效微调等不同的大模型技术。

惠每科技算法团队携惠每医疗大模型参加了参数高效微调赛道。经过近3个月的紧张测试,最终惠每医疗大模型从362支队伍中脱颖而出,以71.3822的综合评分获得该赛道第一名。

糖尿病作为一种典型慢性疾病已成为全球重大公共卫生挑战之一。随着互联网的快速发展,庞大的2型糖尿病患者和高危人群对糖尿病专业信息获取的需求日益突出。为提升自动问答服务对患者和高危人群日常的健康服务能力,大赛设置了中文糖尿病问题分类评测任务,旨在自动为患者提出的有关糖尿病问题进行分类,增强搜索结果的性能并推动糖尿病自动问答服务的发展。
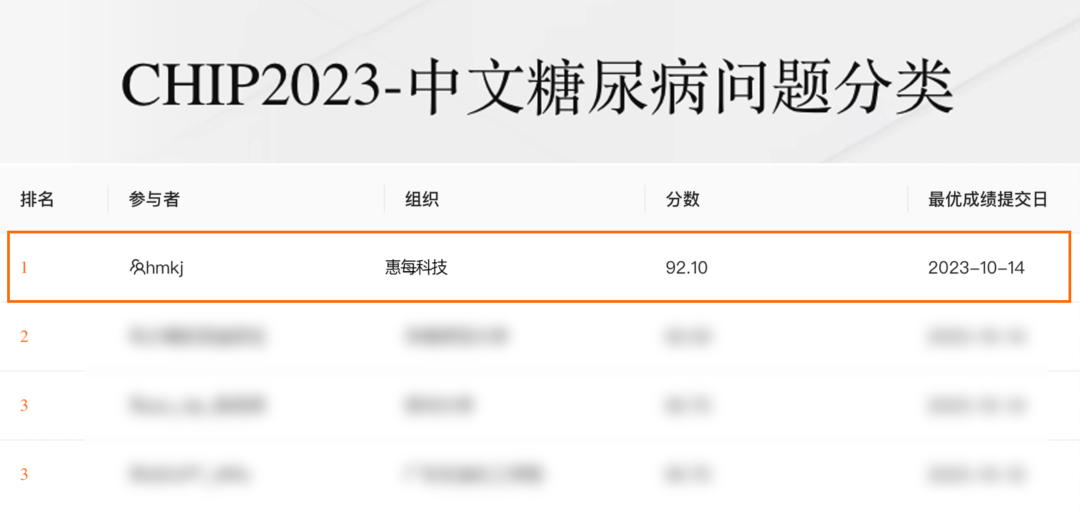
惠每科技算法团队此次同时参加了中文糖尿病问题分类评测任务,针对诊断、治疗、常识、健康生活方式、流行病学等6类问题测试了6000条数据,最终在276个团队中以92.10的综合评分获得该赛道的第一名。
10月27日—29日,CHIP2023在杭州举行,来自香港理工大学、中国科学技术大学生物医学工程学院、浙江大学医学院附属邵逸夫医院的多位专家等出席并作报告。
惠每医疗大模型评测论文在知名期刊刊登
10月28日,由惠每科技算法团队凌鸿顺、葛承泽、王杰等成员撰写的论文《Advanced PromptCBLUE Performance: A Novel Approach Leveraging Large Language Models》被CCKS 2023收录于论文集,在《Communications in Computer and Information Science》(CCIS)第1923期刊登。
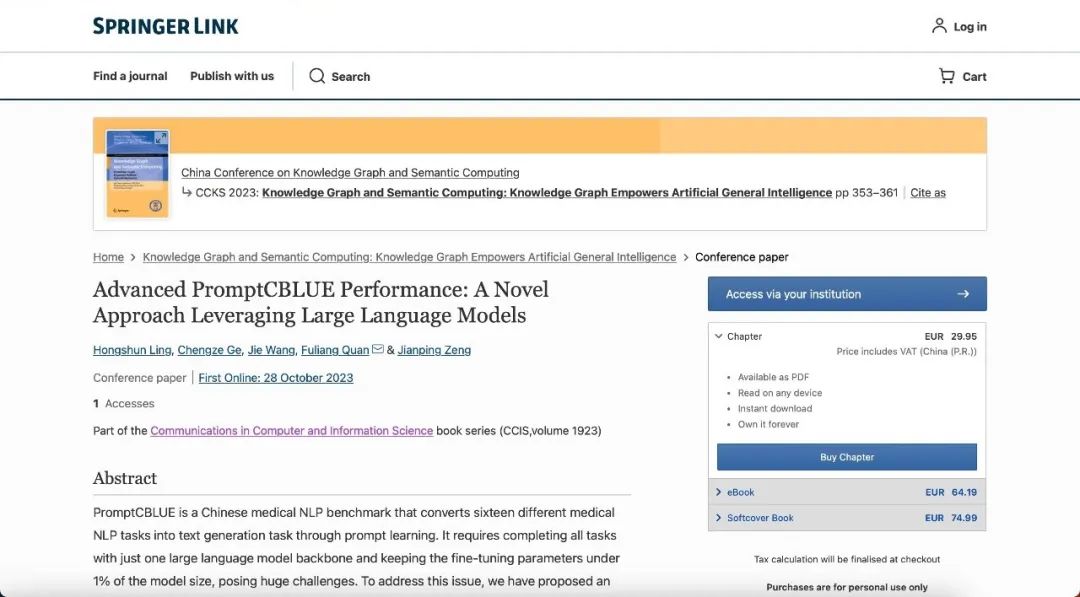
今年8月,由中国中文信息学会语言与知识计算专业委员会主办的第十七届全国知识图谱与语义计算大会(CCKS 2023)在沈阳召开。会上公布了CCKS 2023评测竞赛结果,惠每科技算法团队从396支参赛队伍中脱颖而出,荣获“PromptCBLUE医疗大模型评测”通用赛道第二名。此次刊发的论文内容正来自CCKS 2023的评测过程和结果。
CCIS是世界上最有影响的科技出版集团之一Springer旗下的会议论文集系列,致力于传播最新原创科研成果,覆盖计算机科学和信息通信科学的所有相关方向,从基础理论、技术方法,到重要的应用和相关交叉领域。
CCKS自2016年首次创办开始就将历届大会优秀论文收录于论文集,并在CCIS刊登。2023年收录的论文集名为《Knowledge Graph and Semantic Computing: Knowledge Graph Empowers Artificial General Intelligence》,共收录了28篇论文。
惠每医疗大模型加速方案在沪展示
10月17日,惠每科技CTO王实受邀参加由阿里云主办的上海国际生物医药产业周——阿里云医药数字化同期论坛,介绍了惠每医疗大模型低成本实现医院私有化部署的方法和优势。

王实表示,目前国产大模型发展迅速,在垂直领域的落地能力和客户价值逐渐成为关键点。在医疗行业,数据不能离开医院内网、医院难以负担GPU成本等问题似乎限制了大模型的应用场景。为此,惠每科技联合英特尔共同探索了基于CPU芯片进行大模型推理的技术,帮助医院实现低成本使用大模型。
实际应用中,惠每医疗大模型可在鉴别诊断和病历生成等场景发挥作用,其效果在此前某三甲医院的应用中也得到了医生的初步认可:在没有强制展示的情况下,鉴别诊断使用率达到23%以上,出院小结使用率达到15%以上。
想了解更多产品信息或预约产品演示?我们的专业团队随时为您服务