 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文2023-11-23 关键词: 医疗大模型
为验证惠每医疗大模型的算法能力,2023年8月惠每科技算法团队参加了第九届中国健康信息处理大会(CHIP 2023)评测任务,并在CHIP-PromptCBLUE医疗大模型评测和中文糖尿病问题分类评测两项任务中,分别获得了综合评分的第一名。
本文以CHIP-PromptCBLUE医疗大模型评测过程中的优化方案为例,将此次参评的经验进行了总结和提炼。

评测任务:考察大模型两个能力
CHIP-PromptCBLUE医疗大模型评测任务是CHIP 2023发布的6项测评任务之一。该评测任务只有一个测试集,但包含多个任务的测试样本,包括CMeEE-V2、IMCS-V2-NER、CMeIE、CHIP-CDEE等18个任务。最终分数取决于各项任务分数的平均分数。
图片
测评任务指令集和大模型识别流程
此次任务重点考察大模型两方面能力:
将输入的病历和输出的实体label转化成指令集输入到LLM模型进行识别与生成;
LLM模型生成的结果使用后处理代码得到对应任务的答案。
在基座模型的使用上面,对比了主办方提供的4个基座模型后,惠每科技算法团队选择了更适合本次任务的“baichuan_13b_chat”。同时,根据评测“可训练参数不超过1%”的要求,团队选择LORA算法对大模型进行高效微调,并将可训练参数占比控制在了0.2098%。
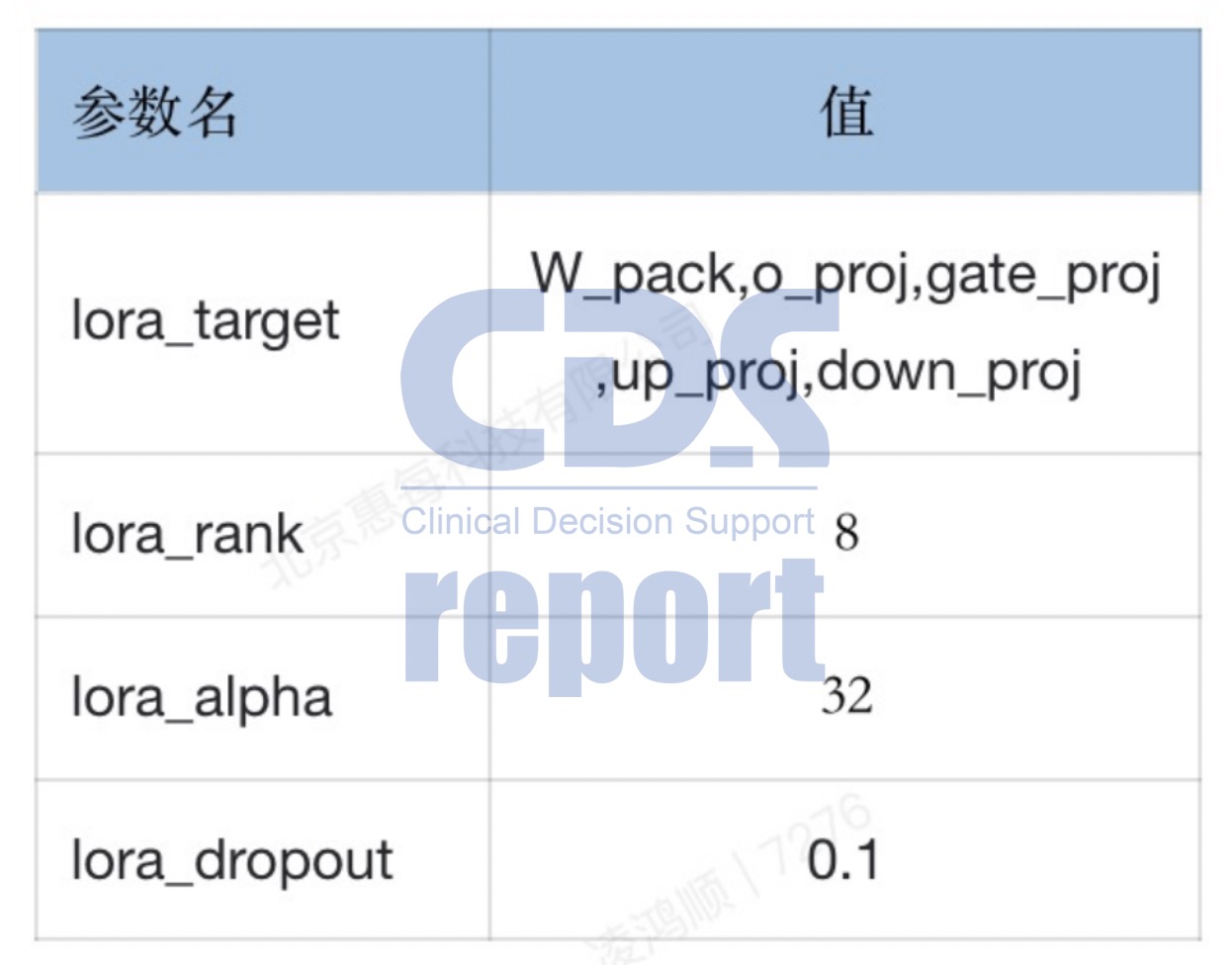
测评中LORA算法相关参数
数据增强方案:8个数据集采样达到16000条
测评主办方使用的训练集数据来自CBLUE,但仅使用了3000条。为了提升大模型能力,算法团队将所有任务的数据集进行了扩充,将CBLUE的16000条数据应用到8个重点测评任务中,包括CHIP-CDEE(临床发现事件抽取)、CMeEE-V2(中文医学命名实体识别)、CHIP-CDN(临床术语标准化)、CMeIE-V2(中文医学文本实体关系抽取)、IMCS-V2-NER(智能对话诊疗数据集NER抽取)、CHIP-MDCFNPC(医疗对话临床发现阴阳性判别)、CHIP-CTC(临床试验筛选标准短文本分类)、CHIP-STS(疾病问答迁移学习)、CMedCausal(医疗因果实体关系抽取)。
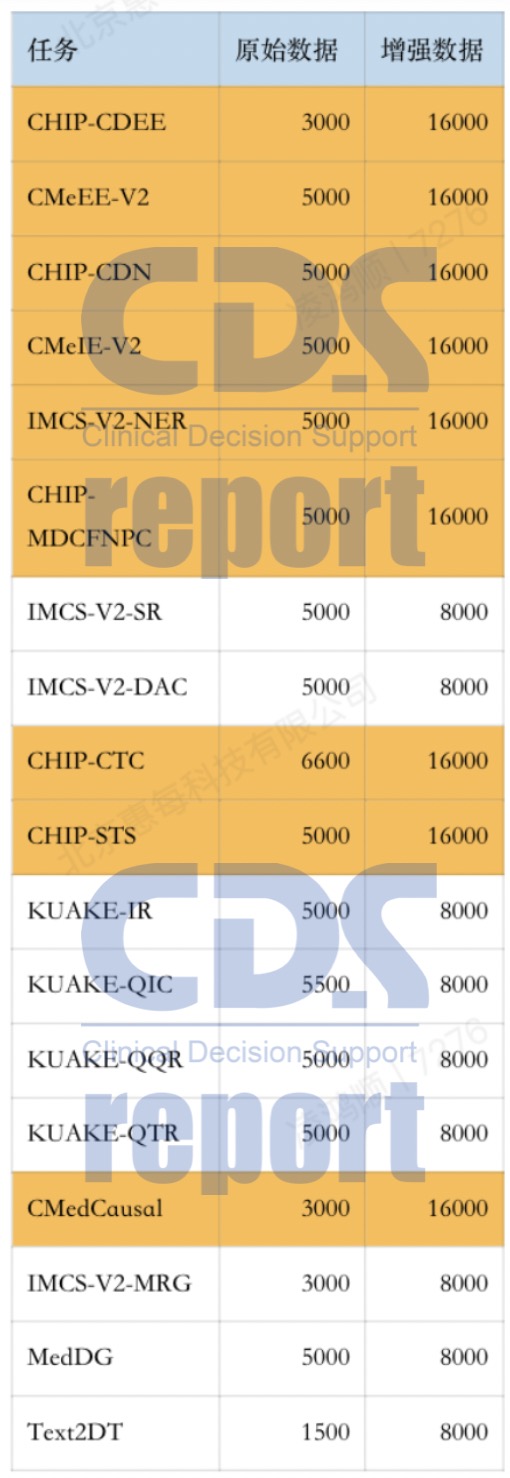
数据增强方案相关数据
对于其余8个数据集,为了保证任务类别的均衡,同样在其原始数据上进行了扩充,扩充数据数量为8000条。
16000条和8000条数据并非空穴来风,而是经过不断的测试和验证,研究人员发现无论是多于还是少于这个数字,都会降低最终任务完成的效果。
focus loss方案:让模型更关注关键实体信息
在进行任务的过程中,团队发现部分生成的语句会比较长,生成结果可能会不精准,后处理测评结果也会受到影响。例如,命名识别任务中模型输出的语句,其句型结构一般来说都是正确的,但对应的关键信息实体以及实体类型出现错误。对此,“如何让大模型区分重要的和不重要的信息”成为需要解决的问题。
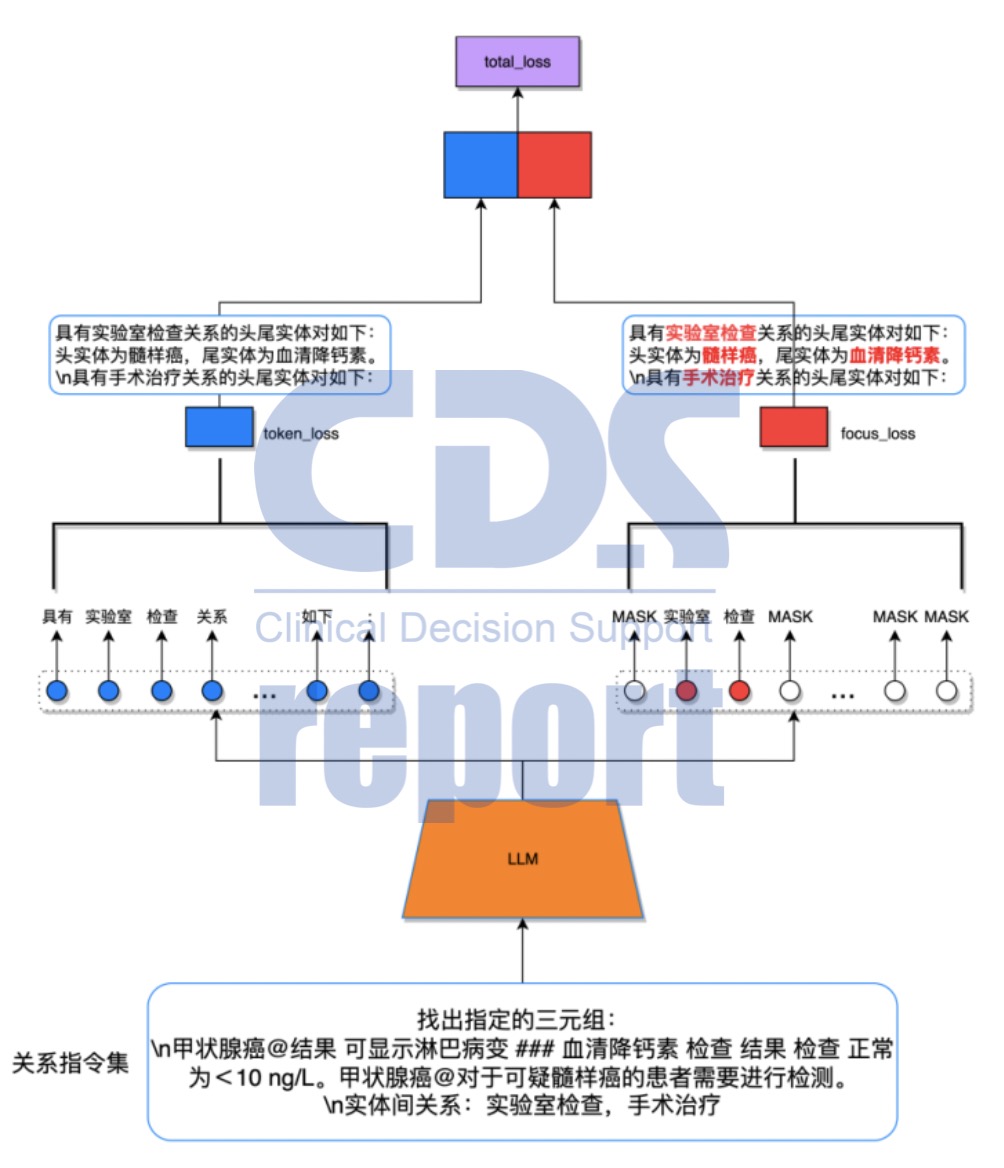
focus loss方案训练流程
经过探讨,团队决定在loss层做出改变:将loss分成两部分进行学习。
首先,将病历原文(关系指令集)输入大模型;然后通过两种方式进行学习,一方面保持默认loss生成方式token_loss,另一方面利用focus_loss只选取重要的实体词;最后将两种方式相加,得到最终的total_loss。
在这个过程中,通过默认loss方式,能够保证语句的连贯性,而focus_loss则可以让大模型更加关注关键实体词。团队还发现,当两种方式以1:1的权重进行训练时,大模型输出结果会过于重视实体词,导致句式出现问题。因此,经过多次尝试,最终团队将focus_loss的权重降低到0.25,将该方案调整到最佳方案。
随机mask方案:将在期刊论文中公布
本次测评能够达成“双料”第一,关键的训练方案“随机mask”功不可没。惠每科技团队已对该训练方案过程和应用效果进行了记录和分析,并被Springer出版社收录,敬请期待。
想了解更多产品信息或预约产品演示?我们的专业团队随时为您服务