 当前位置: AI资讯 > 内文
当前位置: AI资讯 > 内文关键词: 医疗大模型
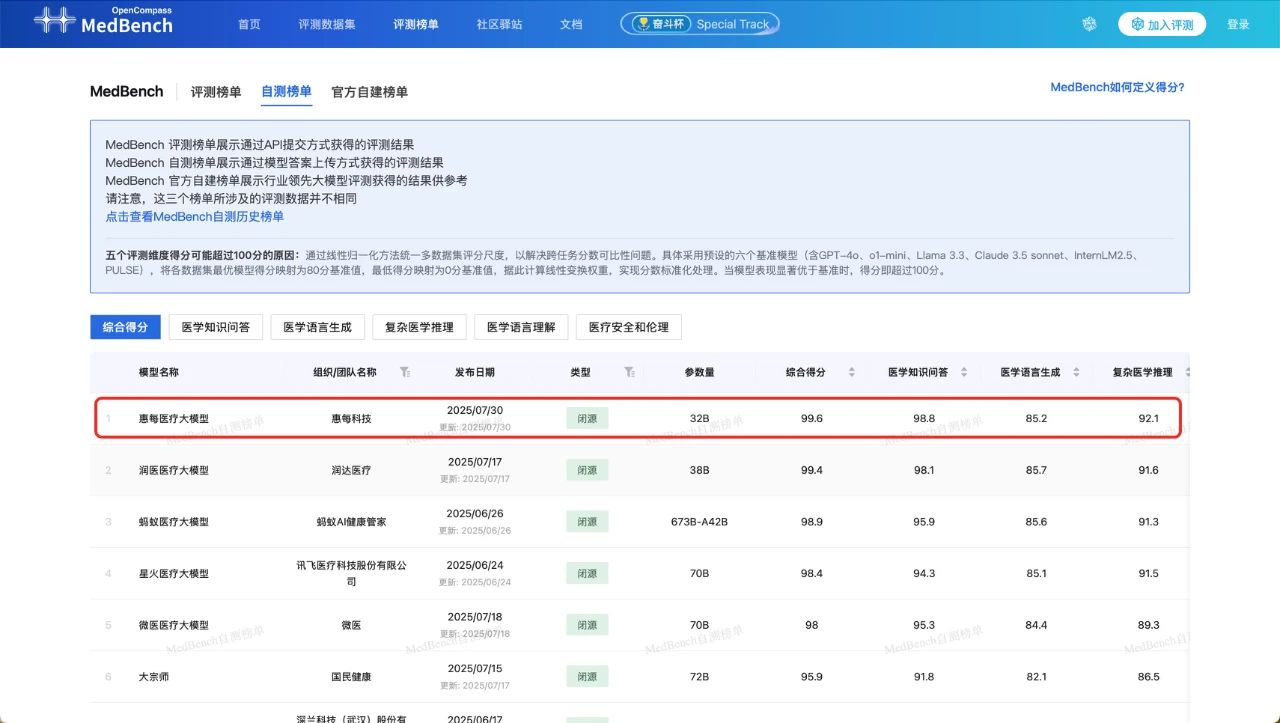
近日,医疗大模型评测平台MedBench发布新版评测榜单,惠每医疗大模型从近60个参评团队中脱颖而出,以99.6分夺得自测榜单综合排名第一名!此外,在5个评测维度中,惠每医疗大模型分别获得医学知识问答、复杂医学推理、医学语言理解、医疗安全和伦理4个维度的最高分。
MedBench作为中文医疗大模型权威评测平台,由上海人工智能实验室、上海市数字医学创新中心联合多家机构打造,已成为全球医疗AI领域重要参照标准之一。目前,平台已累计评测全球387个医疗大模型,从医学语言理解、生成、知识问答、复杂推理及医疗安全伦理五大维度,提供客观科学的性能评估。
继第九届中国健康信息处理大会(CHIP 2023)获得两项大模型测评任务全国冠军之后,惠每医疗大模型再次获得MedBench自测榜单第一名,是对其技术实力和创新能力的有力印证,更奠定了惠每医疗大模型在医疗AI领域的领先地位。在5个评测维度中,惠每医疗大模型分别取得医学知识问答、复杂医学推理、医学语言理解、医疗安全和伦理4个维度的第一名,以及医学语言生成的第三名,显示出其在多领域综合实力的卓越表现,为医疗场景中的广泛应用奠定了坚实基础。
目前,由惠每科技自主研发的惠每医疗大模型已经覆盖临床诊疗、质量管理、疾病风险预警等多个医疗场景,例如临床决策支持、病历质量管理、医保控费等。基于惠每医疗大模型的临床决策支持系统(CDSS)和病历内涵质控系统已经上线国内60余家医院,并在智慧医院建设和医院高质量发展中展现自身价值。
想了解更多产品信息或预约产品演示?我们的专业团队随时为您服务